互联网金融征信服务 以数据为基,以模型为翼
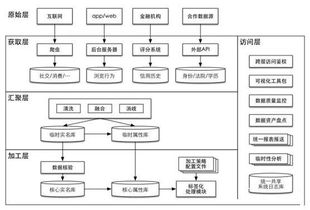
在数字经济蓬勃发展的今天,互联网金融征信服务已成为连接资金供需、评估信用风险、驱动普惠金融落地的核心枢纽。它打破了传统金融在信息获取、覆盖范围与处理效率上的局限,但其健康发展与高效运转,离不开坚实的数据基础与先进的模型工具。可以说,要构建稳健、精准、前瞻的互联网征信体系,必须坚持“数据”与“模型”双轮驱动,先行布局,深度融合。
一、数据先行:构筑征信体系的“数字地基”
数据是征信服务的“生命线”与“原材料”。与传统征信主要依赖信贷历史记录不同,互联网征信的优势在于能够整合多维、海量、动态的替代性数据,从而更全面地刻画个人或企业的信用画像。
- 数据源的多元化与深度挖掘:互联网数据服务提供了广阔的数据来源,包括但不限于:
- 电商交易数据:消费习惯、支付能力、履约记录。
- 社交网络数据:人际关系网络、行为偏好、稳定性信息。
- 公共服务数据:社保、税务、司法、学历等官方或准官方信息。
- 行为数据:设备使用、位置信息、App活跃度等。
* 产业链数据:针对小微企业,其上下游交易、物流、仓储等经营数据。
先行构建广泛、合规、可持续的数据采集与整合能力,是征信服务的第一步。这要求与数据源方建立稳固的合作关系,并确保数据采集的合法性、用户的知情同意与隐私保护。
- 数据治理与质量保障:原始数据往往存在碎片化、噪声大、格式不一等问题。因此,必须先行建立一套完善的数据治理体系,包括数据清洗、标准化、关联整合、质量监控等环节。高质量、结构化、可追溯的数据是后续一切分析与建模工作的基础,直接决定了征信产品的准确性与可靠性。
- 数据安全与合规底线:在数据先行过程中,必须将安全与合规置于首位。严格遵守《个人信息保护法》《数据安全法》等法律法规,建立健全数据分级分类保护、加密传输存储、访问权限控制、隐私计算应用等机制,确保数据在合法合规的框架内被善用,是行业可持续发展的生命线。
二、模型先行:锻造信用评估的“智能引擎”
当海量数据就绪后,如何从中提炼出有价值的信用洞察,则依赖于先进的模型算法。模型是将数据转化为信用风险量化判断的“转换器”与“决策脑”。
- 模型体系的创新与迭代:传统的逻辑回归等统计方法已难以完全适应互联网数据的复杂非线性关系。机器学习、深度学习等人工智能技术成为模型先行的关键。需要先行研发和部署适合不同场景的信用评分模型、反欺诈模型、行为预测模型、授信定价模型等。例如:
- 图神经网络模型:用于分析用户社交关系网络中的风险传导。
- 时序预测模型:用于基于用户历史行为序列预测未来还款概率。
* 集成学习模型:融合多种弱学习器,提升模型的整体稳健性与准确性。
模型的研发需要前瞻性布局,持续迭代优化,以适应市场变化和新型风险。
- 特征工程与可解释性:模型的效果很大程度上取决于输入的特征。从原始数据中构建出能有效区分信用好坏的特征(如“近三个月夜间交易占比”、“社交圈稳定性指数”等),是模型团队的核心能力之一。随着监管对算法透明度的要求提高,模型的可解释性变得至关重要。需要发展如SHAP、LIME等解释工具,使模型的决策逻辑能够被理解和验证,避免“算法黑箱”带来的歧视与不公。
- 模型风险管理与验证:模型本身也存在风险(如过拟合、概念漂移等)。必须先行建立独立的模型风险管理体系,包括模型开发、验证、审批、监控、退役的全生命周期管理。定期进行回溯测试和压力测试,确保模型在复杂经济环境下的稳定性和预测能力。
三、数据与模型的融合共生:驱动服务升级
数据与模型并非孤立存在,而是相互促进、迭代演进的共生关系。优质数据喂养了更精准的模型,而更先进的模型又能指导更有效的数据采集与特征构建,形成正向循环。
- 在服务普惠金融上:通过融合多维度互联网数据与智能模型,可以为缺乏传统信贷记录的“信用白户”(如小微企业主、蓝领工人、年轻消费者等)提供有效的信用评估,扩大金融服务的可得性。
- 在动态风险监控上:实时或准实时的数据流结合在线学习模型,可以实现对借款人信用状况的动态监控与早期风险预警,提升贷后管理效率。
- 在产品创新上:基于细颗粒度的数据与模型,可以开发出更个性化、场景化的信用产品,如“先用后付”的消费信贷、基于交易流的供应链金融等。
###
互联网金融征信服务的核心竞争力,日益体现在其对数据和模型的驾驭能力上。坚持“数据先行”,筑牢合规、多元、高质量的数据基础;坚持“模型先行”,打造智能、精准、可解释的算法引擎。唯有两者协同并进,深度融合,方能构建起一个既包容普惠又安全稳健的现代征信生态系统,真正赋能金融创新,服务实体经济,最终惠及广大用户。这条“数据+模型”的先行之路,是行业走向成熟与卓越的必由之路。
如若转载,请注明出处:http://www.yinseshow.com/product/77.html
更新时间:2026-06-19 22:05:29